
[Tutorial] Develop a simple RAG App
From Theory to Implementation: Building RAG application with External Knowledge

Workshop Video:
Understanding RAG: A Deep Dive into Retrieval Augmented Generation
In a recent technical workshop, we explored the fundamentals and implementation details of Retrieval Augmented Generation (RAG), a powerful technique that enhances Large Language Models (LLMs) with external knowledge. Here's a comprehensive overview of what we learned.
What is RAG?
Retrieval Augmented Generation is a method that combines the power of LLMs with the ability to access and use external data. Instead of relying solely on an LLM's trained knowledge, RAG allows us to supplement it with specific information from our own documents and data sources.
Basic RAG Workflow
Below is a diagram showing the basic workflow of a RAG system:
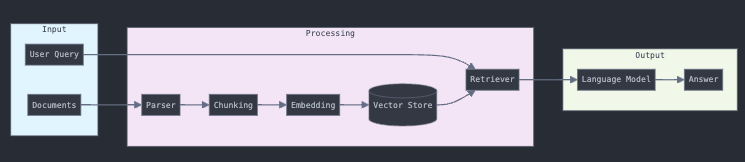
Let's implement a basic RAG system using LlamaIndex and OpenAI:
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
# Initialize LLM and embeddings
llm = OpenAI(model="gpt-4o-mini")
Settings.llm = llm
Settings.embed_model = OpenAIEmbedding()
# Load documents and create index
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents, show_progress=True)
# Create query engine
query_engine = index.as_query_engine()The workflow consists of three main stages:
Input processing (documents and queries)
Vector processing and retrieval
LLM-based answer generation
Why Use RAG?
Several compelling reasons make RAG an essential tool in modern AI applications:
Context Window Optimization: When dealing with large documents (e.g., 5,000 paragraphs), we can't simply dump everything into the LLM due to context window limitations.
Cost Efficiency: OpenAI and similar services charge based on both input and output tokens. RAG helps minimize costs by only using relevant portions of your data.
Accuracy Improvement: By providing specific, relevant information, RAG can help reduce hallucinations and improve the accuracy of responses.
Key Components of RAG
1. Document Chunking
One of the most critical aspects of RAG implementation is how you chunk your data. Different chunking strategies can be employed based on your specific needs:
The choice of chunking strategy can significantly impact the quality of your RAG system:
Fixed-size chunks are simple but may break contextual relationships
Paragraph-based chunking preserves natural text boundaries
Semantic chunking maintains topical coherence
Hybrid approaches combine multiple strategies for optimal results
Sample code for sentence wise chunking
from llama_index.core.node_parser import SentenceSplitter
# Create a sentence splitter with specific chunk size and overlap
splitter = SentenceSplitter(
chunk_size=1024,
chunk_overlap=20,
)
# Get nodes from documents
nodes = splitter.get_nodes_from_documents(documents)2. Embeddings and Similarity Search
The embedding and similarity search process is at the heart of RAG:
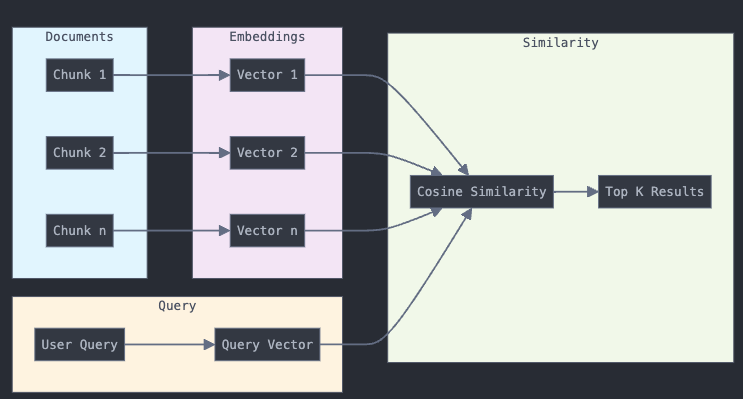
Sample Code for embeddings
# OpenAI embeddings
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding()
# Or use open-source alternatives
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
# Create index with specific embedding model
index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)This process involves:
Converting text chunks into vector embeddings
Processing user queries into the same vector space
Performing similarity searches to find relevant content
Retrieving the most relevant chunks for the LLM
Key considerations for embeddings:
Each paragraph or chunk of text is converted into a vector of approximately 1,000 dimensions
These vectors allow for similarity comparisons between queries and stored content
Different embedding models can be used based on your specific needs
3. Storage and Management
Embeddings can be stored locally or in vector databases like Pinecone
Proper storage is crucial for maintaining persistence between sessions
Vector databases optimize retrieval speed and efficiency
import os.path
from llama_index.core import StorageContext, load_index_from_storage
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# Create and store index
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# Load existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)Implementation Best Practices
Parsing Considerations
When working with different document types:
Use specialized parsers for different file formats (PDF, PPT, Excel, etc.)
Consider using LlamaIndex or Unstructured library for robust parsing
Be aware of parsing challenges with tables and images
Improving RAG Performance
To optimize your RAG implementation:
Benchmark Different Embeddings:
Test various embedding models
Compare retrieval accuracy
Monitor performance metrics
Optimize Chunking:
Experiment with different chunk sizes
Test various overlap strategies
Consider domain-specific chunking approaches
Consider Multimodal Options:
Integrate image processing when needed
Use specialized models for different content types
Combine text and image embeddings when appropriate
Conclusion
RAG represents a powerful approach to enhancing LLM capabilities with specific, relevant information. The code examples provided show how relatively straightforward it can be to implement a basic RAG system, while the concepts discussed highlight the depth and complexity available for more advanced implementations.
Key takeaways:
Start with basic implementations and iteratively improve
Pay attention to chunking and embedding strategies
Consider persistence and performance requirements
Test thoroughly with your specific use case
Remember that RAG is not just about implementation - it's about finding the right balance between complexity, cost, and effectiveness for your specific use case.