
Multi-Agent AI for Structural Engineering in AEC
How MASSE uses role-based AI agents, structured memory, and FEM tools to speed up structural workflows plus what it implies for AEC teams.

The authors state the methods, code, and data are for academic research and educational use only and should not be relied on for real-world engineering design, construction, or deployment.
With that out of the way, the paper is still valuable because it shows how to structure AI systems so engineering work becomes more auditable, tool-driven, and less brittle.
The problem MASSE is tackling
Structural engineering work isn’t one big “answer.” It’s a chain:
pull seismic/climate parameters from codes
extract geometry/materials from drawings/descriptions
compute section properties and capacities
build/run a finite element model
compare demand vs capacity
iterate if it fails
The paper argues this traditional workflow is time-consuming, error-prone, and hard to scale, especially for cases like warehouse racking where there are many repeated designs.
MASSE is their proposed automation framework.
What MASSE is and how it’s organized
MASSE is a multi-agent system tailored to structural design tasks, designed to mirror how an engineering consultancy splits work across roles.
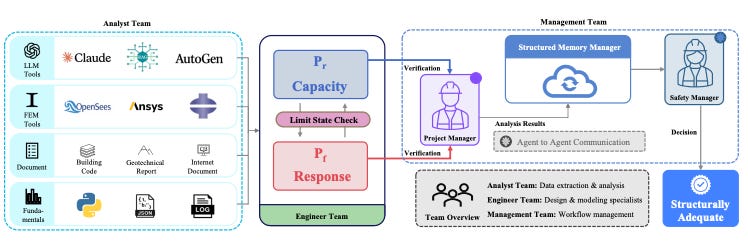
Three “teams,” like a small consulting group
Analyst Team: converts messy descriptions + documents into standardized engineering inputs (loads, extracted info, model-ready data).
Engineer Team: runs analysis, design, and adequacy checks using the prepared inputs (including simulations + capacity checks).
Management Team: coordinates and issues the final safety conclusion; the Safety Manager delivers the final adequacy verdict.
The overall framework diagram also emphasizes structured memory and the final “adequacy decision” step.
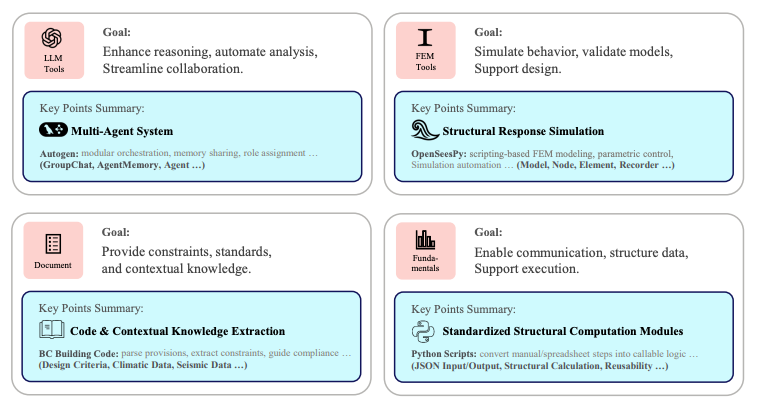
It’s “LLM + tools,” not just text
The system is described as integrating multiple layers: LLM tools, FEM solvers, engineering documents/codes, and fundamentals.
They mention using embedding models (example given: text-embedding-3) to support retrieval-augmented generation for accessing building codes and technical documents.
The key implementation choice: structured communication
The paper is unusually blunt about this: relying on verbose natural-language back-and-forth can degrade performance on long-horizon structural tasks because it can overflow context windows and obscure details.
So MASSE uses structured communication paradigms:
JSON-based input/output schemas
turn-level state tracking
…to keep outputs concise and verifiable.
If you’re an AEC tech builder reading this, that’s one of the most “buildable” lessons in the whole paper.
Evidence that decomposition matters single-agent vs multi-agent
In Appendix A, the authors run a controlled comparison for generating OpenSeesPy scripts from natural-language problem descriptions:
Two-agent system: one agent extracts parameters into JSON + computes section properties, another generates the full OpenSeesPy script.
Single-agent system: directly produces executable scripts in one step.
Result:
single-agent failed in all 10 trials
multi-agent succeeded in every trial
They also show a failure-mode distribution for the single-agent setup: dependency (50%), logic (30%), formatting (20%).
The takeaway isn’t “LLMs can’t do engineering.” It’s: long, tool-mediated chains break when you force one agent to do everything at once.
What they tested MASSE on and how they measured it
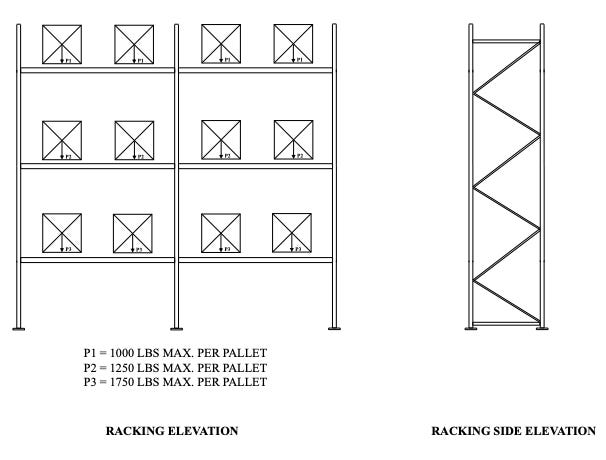
They evaluate MASSE using a racking-system design scenario and build a dataset of 100 scenarios validated with expert-derived ground-truth solutions.
They also describe the dataset as derived from real-world racking projects in British Columbia, Canada.
Benchmarks include:
structural analysis agent performance (OpenSeesPy model construction + result retrieval)
structural design agent performance (capacity/property computations + memory transfer)
loading agent performance (extract info + RAG on documents + determine loads)
a holistic multi-agent benchmark (MASEB)
They use GPT-5 as an LLM judge to score outputs against expert-verified ground truth (Appendix E.2.1).
Two results that matter for AEC practitioners
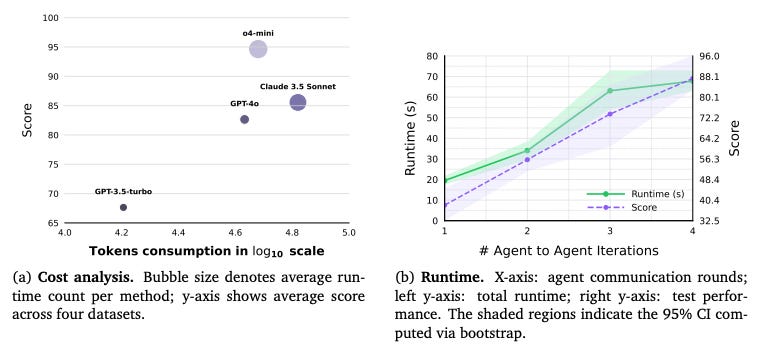
1) Structured memory + JSON I/O are “not optional”
They run an ablation study on two components:
agent memory (M)
JSON format (J)
The combination (+M, J) performs best across benchmarks, and the paper states the baseline without either yields the lowest scores.
2) Human evaluation: time compression for the tested task
They report a comparative study with 11 experienced structural engineers doing a standardized racking design task:
conventional workflow average: 132 minutes
MASSE (powered by GPT-4o) average: ~2 minutes
“over 98%” reduction
Why this architecture is interesting for AEC what the paper implies
In the discussion, the authors emphasize verifiable processes, logged artifacts, deterministic outputs for reproducible checks, and “localized error handling” to prevent small mistakes from cascading.
They frame MASSE as acting like a junior engineer whose steps are fully auditable supporting transparency/traceability without “uncontrolled autonomy.”
That framing is basically the bridge to broader AEC: systems that generate structured intermediate outputs for senior verification.
Potential AEC extensions
I’m flagging these explicitly as “potential” so we don’t smuggle them in as facts.
If you take the MASSE pattern role-specialized agents + tool calls + structured memory + safety gate here are plausible AEC places it could map:
Plan/permit review prep (extract constraints from code sections into structured checklists) MASSE already emphasizes code/document retrieval via embeddings + structured protocols.
Engineering QA/QC packaging (log every artifact, keep deterministic outputs, prevent cascades) aligns with the paper’s transparency/determinism goals.
Repeated, template-heavy scopes (where workflows are procedural and tool-mediated) the authors explicitly describe structural engineering as procedural/tool-centric and say single LLM accuracy collapses when multi-tool chains are needed.
The safe claim here is not “MASSE will do all this.” The safe claim is: the architecture is designed for domains where tasks are verbalizable, procedural, and tool-mediated and AEC has a lot of that shape.
The main takeaway
MASSE is a proof-of-concept showing that if you want AI to behave more like engineering work, you don’t just scale a single model you:
decompose into roles (Analyst → Engineer → Manager/Safety)
embed tools and documents in the loop
force structured communication + memory for auditability
keep human responsibility explicit
and (in their tested setting) you can compress a task from hours to minutes
This blog post is based on research by Haoran Liang, Yufa Zhou, Mohammad Talebi–Kalaleh, and Qipei Mei, published in the paper “Automating Structural Engineering Workflows with Large Language Model Agents”
Very interesting paper. Thank you for sharing! I am building something similar but for the compliance side with building codes.