
How LLM Embeddings Improve BIM AI Understanding
Learn how LLM embeddings enhance AI training in BIM by preserving building semantics and improving subtype classification accuracy.

Most AI models in AEC don’t struggle because of lack of data.
They struggle because of how that data is represented during training.
This paper focuses on one specific issue:
How do you encode building elements so AI can better distinguish between similar subtypes?
Examples:
Core wall vs partition wall
Bathroom slab vs structural slab
These aren’t just labels, they carry semantic meaning.
The Core Technical Problem
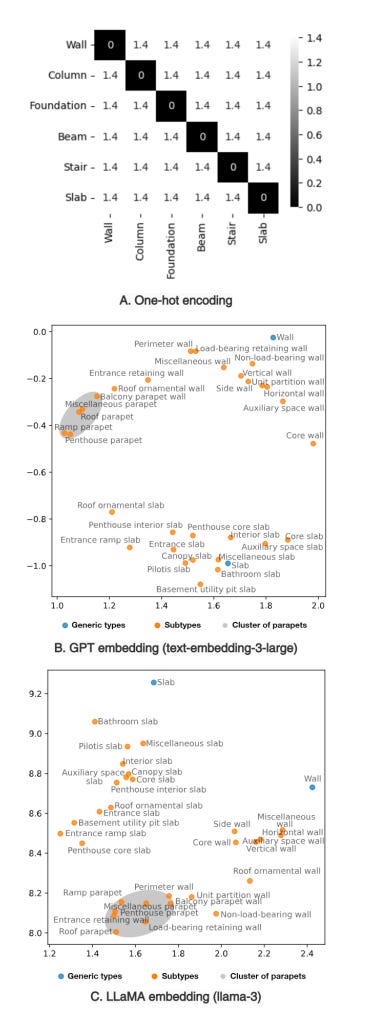
Most models use one-hot encoding.
That means each class is treated as completely independent:
No relationship between “wall” and “parapet wall”
No similarity between different slab types
So the model learns:
Categories are different but not how they are different.
The Proposed Solution: LLM Embeddings as Encodings
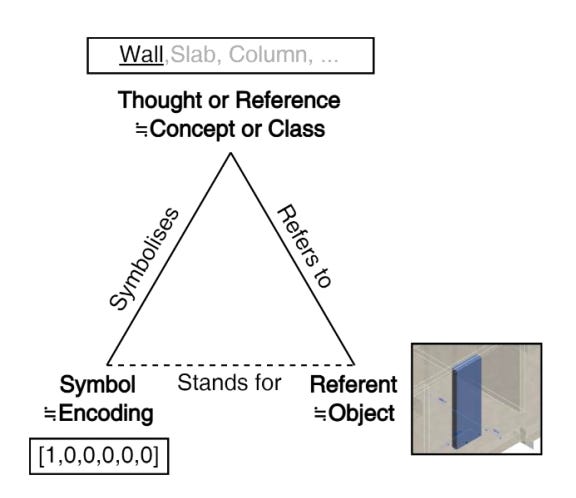
Instead of using fixed labels, the paper uses LLM-generated embeddings:
Each class is represented as a vector with semantic structure
Similar classes are closer in vector space
Differences between subtypes are preserved
As shown in the visualization on page 3, LLM embeddings form clusters of related subtypes, unlike one-hot encoding which has no notion of similarity.
How Training Changes
This isn’t just swapping inputs, it changes the training process.
Instead of:
Predicting a class label
The model:
Outputs an embedding vector
Compares it to the target embedding
Uses cosine similarity loss to measure alignment
So learning becomes:
“Match the meaning of the class,” not just “pick the correct label.”
Experimental Setup
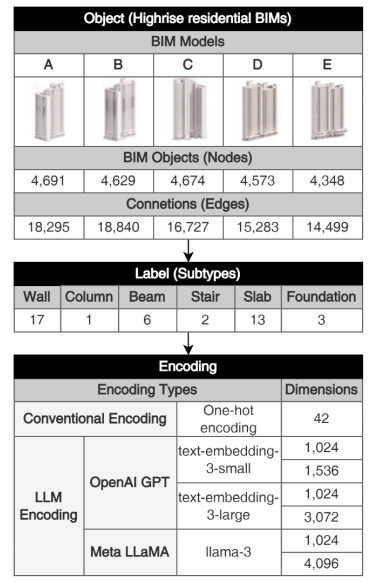
Model: GraphSAGE (3 layers, 1024-dim output)
Data: 5 high-rise residential BIM models
Classes: 42 building subtypes (see table on page 5)
Encodings tested:
One-hot (baseline)
OpenAI embeddings (small + large)
LLaMA embeddings
Both original and compressed (Matryoshka → 1024-dim)
Results
One-hot encoding: F1 = 0.8475
Best result (LLaMA, compacted): F1 = 0.8766
What this means:
There is a consistent improvement
But the gain is moderate (~3–4%)
Important nuance:
Statistical tests show limited significance across comparisons
Only one configuration showed clear statistical significance
👉 So this is promising but not conclusive.
Key Technical Insight
Compressed embeddings (1024-dim) often performed better than larger ones.
Likely reason (based on setup):
Model output is 1024-dim
Larger embeddings may not be fully utilized
Compression preserves key semantics while aligning with model capacity
What This Means for AEC
1. Better Subtype Classification in BIM
This is the direct, validated outcome.
More accurate classification of detailed building elements
Better distinction between similar subtypes
2. Improved Semantic Enrichment Workflows
Enhancing BIM data with richer semantic labels
Supporting downstream AI tasks that depend on correct classification
3. More Meaningful Training Signals
One-hot → rigid labels
LLM embeddings → semantic relationships
This shift improves how models learn differences between building elements.
Where This Could Go
The paper does not test these directly, but the approach could extend to:
Other semantic tasks (e.g., scheduling, design intent understanding)
Multimodal AI systems (text + geometry + point clouds)
Domain-specific LLM embeddings trained on construction data
These directions are discussed in the paper but not experimentally validated.
Limitations
Only tested on 5 residential BIM projects
Focused on a classification task only
Uses general-purpose LLM embeddings
Improvements are not uniformly statistically significant
Final Takeaway
This paper doesn’t introduce a new model.
It introduces a different way to represent labels during training.
And that small shift:
From discrete labels → semantic embeddings
leads to more nuanced learning of building elements.
It’s not a breakthrough but it’s a meaningful step toward more context-aware AI in AEC.
This blog post is based on research by Suhyung Jang, Ghang Lee, Jaekun Lee, and Hyunjun Lee, published in the paper “Enhancing Building Semantics Preservation in AI Model Training with Large Language Model Encodings.”
If you are exploring ai in construction or need support in GTM for your construction tech startup, book a discovery call using this link :
https://calendly.com/mayur-mistry7/consultancy-discovery-call