
Few-Shot Robot Learning for Construction Tasks
Benchmarking VLA vs DQN for panel pickup and insertion in simulation, what it means for construction robotics, demos, and deployment.

Few-Shot Robot Skills for Construction: VLA vs DQN in a Panel Task
Most construction robotics conversations hit the same wall:
“The robot did the demo… but how hard is it to teach it the next version of the task?”
This paper tackles that question in a very practical way: it benchmarks Reinforcement Learning-style imitation (DQN/MLP) against Vision–Language–Action (VLA) models for construction-flavored manipulation, and it explicitly evaluates not just performance, but the effort needed to get something working.
The headline claim is straightforward:
VLA shows few-shot capability in the pickup phase (reported as 60% and 100% success in two scenes).
DQN can reach similar pickup success, but they report it needed additional noise during tuning, increasing workload.
Let’s unpack what they actually built, tested, and what it implies for AEC teams trying to operationalize robot learning.
1) What they tested and Why it maps to construction work
Two simulated “workplaces,” two robot arms, one core manipulation pattern
All experiments are conducted in MuJoCo, following settings from LIBERO and Robosuite, and they construct:
a ground-level scene with a UR5e arm
a desk-level scene with a Franka Panda arm
All robots use an adhesion gripper.
The tasks are panel-centric and long-horizon. The paper describes:
desk workplace: pick up a panel from a desk and place it onto a stand
ground workplace: lift a panel from the ground and insert it into a tilted frame
That “pickup → move → align/insert” shape is relevant because a lot of AEC manipulation work fails not on grasping, but on alignment and placement.
2) The most “implementation-real” part: how they collect demonstrations
The authors build two teleoperation interfaces explicitly to make demo collection practical:
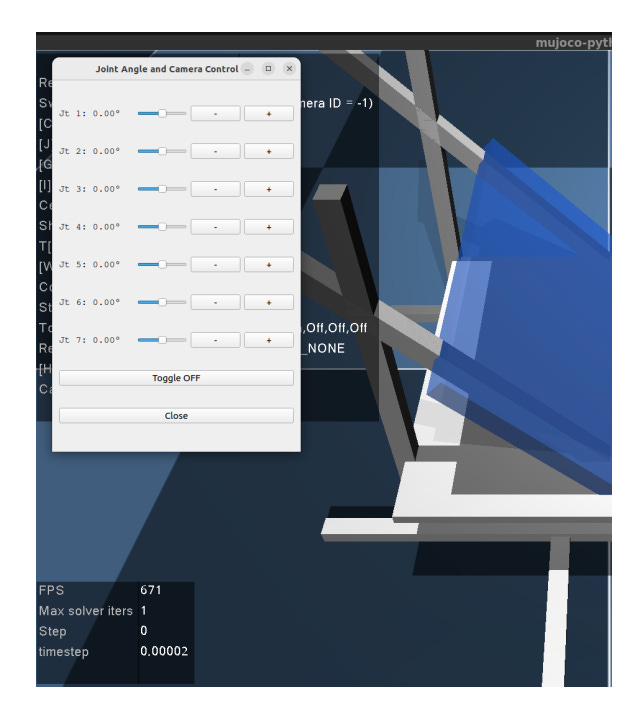
(A) Joint-angle sliders
joint motion control with 0.1 rad precision
returns (1) 7-DoF object pose, (2) robot joint states, (3) collision force
sim sampling can reach 100 Hz; they apply a filtering window of 25 twice to reduce noise for learning
They also note the demonstrator practiced first, and started formal collection once they could minimize collision forces during installation.
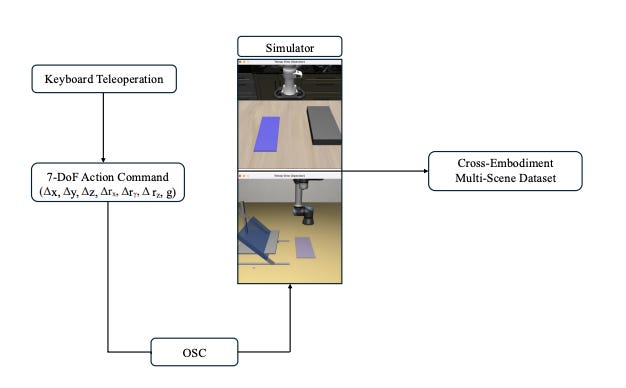
(B) Keyboard end-effector teleop
For VLA-oriented demos:
7-DoF end-effector actions at 20 Hz
actions are continuous deltas
[Δx, Δy, Δz, Δrx, Δry, Δrz, g]they use an Operational Space Controller (OSC) to convert Cartesian deltas into low-level commands/torques for smooth, physically consistent demonstrations
Episodes are recorded with:
synchronized agent-view RGB (256×256) and wrist-camera images
proprioceptive states + 7-DoF actions
paired natural-language instruction
stored in an RLDS-compatible format
If you’re thinking “this sounds like the hard part,” you’re not wrong. But it’s also the most transferable piece for AEC teams: a repeatable path from “operator demo” → “fine-tuning dataset.”
3) The benchmark design (three-stage evaluation)
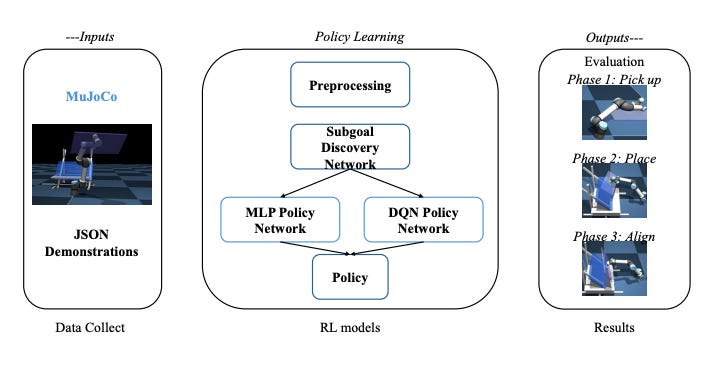
The evaluation is intentionally staged:
Stage I: MLP vs DQN imitation policy to pick the stronger RL baseline
Stage II: compare VLA models (π0 vs π0.5 vs OpenVLA)
Stage III: benchmark selected RL baseline vs VLA using (a) computational/sample-efficiency measures and (b) a dual-phase panel installation task (pickup + dexterity-required installation phase)
4) What actually won
Stage I: DQN vs MLP
Both hit 100% pickup success on the reported metric, but:
MLP shows overfitting
DQN does not
They choose DQN for later experiments.
Stage II: VLA models
Reported success rates:
π0 (desk): pickup 60%, place 44%, align 32%
π0.5 (ground): pickup 100%, place 96%, align 80%
OpenVLA: 0% across both scenes/tasks
The paper’s explanation for why π0 and π0.5 do better emphasizes:
multi-view perception
continuous action head enabling smooth control
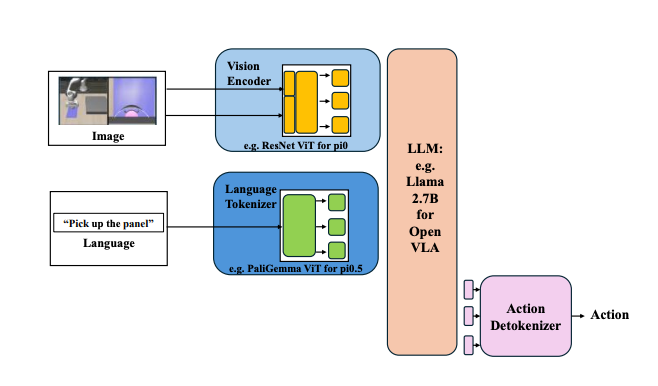
5) Why architecture mattered here (VLA details, grounded)
The paper gives unusually concrete details on the VLA variants:
π0 (multi-view + continuous action chunk)
uses a PaLI-Gemma-3B vision-language backbone (ViT encoder + Gemma decoder)
fuses agent + wrist RGB + text prompt into the model
action expert predicts a 50-step chunk of continuous end-effector deltas + gripper commands, enabling control up to ~50 Hz on contact tasks
They also note π0 is ~3.3B parameters in their setup (3B VLM + ~300M action expert).
π0.5 (same interface, “reason-then-act”)
preserves π0’s I/O and control interface
at inference: produces a high-level subtask in language, then realizes it with a continuous 50-step action chunk
OpenVLA (single-view + discrete actions)
OpenVLA removes:
multi-view RGB
continuous expert head
Instead it:
predicts actions as discrete tokens by discretizing each action dimension into 256 bins
uses a single agent-view image (per their configuration)
And in this benchmark, it gets 0% success.
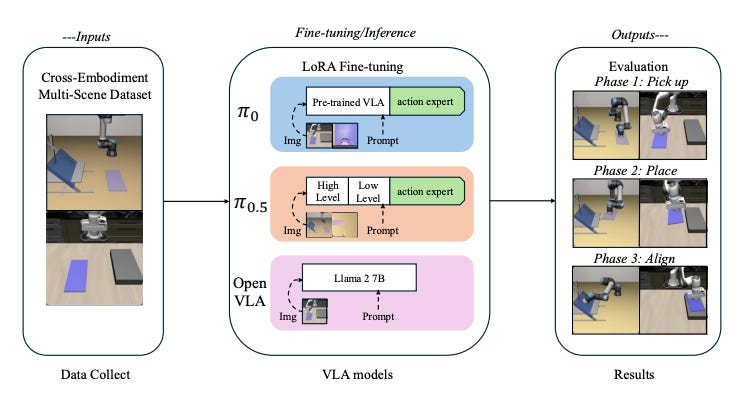
Fine-tuning approach across VLA models
All VLA models are initialized from public checkpoints and adapted using parameter-efficient LoRA adapters on their dataset.
6) So what does this mean for AEC teams?
The paper’s experiments are in simulation, but the workflow components map cleanly to real AEC robotics programs especially if you’re doing manipulation where “alignment” is the painful part.
Implication 1: If you care about placement/alignment, smooth continuous control and good viewpoints seem critical
In this benchmark, the best-performing VLA setups are explicitly associated with multi-view perception + continuous control, and the single-view + discrete-action baseline fails.
What that suggests (not proves): tasks that look like “insert panel into frame” may be more sensitive to perception coverage and control smoothness than “simple pick and move.”
Implication 2: Demonstration infrastructure is a practical differentiator
A lot of teams focus on model choice first. This paper quietly argues the opposite by building two demo interfaces and showing how those demos become:
RL training inputs (states/forces/joints/object pose)
VLA fine-tuning data (multi-view RGB + actions + language)
If you’re thinking about a pilot, copying their data capture discipline is likely more immediately useful than debating model families.
Implication 3: “Few-shot” is being treated as a deployment lever
The authors explicitly frame VLA as reducing programming effort and enabling useful performance with minimal data, while DQN is viable if you accept more tuning effort.
For AEC integration, that could matter most in environments where tasks vary across projects/sites, because the cost of reprogramming is often the real blocker not the robot hardware.
7) A grounded implementation path what you can do without overpromising
If you’re an AEC tech team trying to operationalize the “learning from demos” approach described here, a conservative sequence would look like:
Start with a bounded manipulation task shaped like their benchmark (pickup → place → align/insert), because the evaluation and metrics are well-defined around these phases.
Build the demo pipeline first, not last:
precision mode: joint sliders returning object pose, joint states, collision force
scale mode: keyboard end-effector deltas + OSC conversion + synchronized multi-view recording
Adopt parameter-efficient adaptation (LoRA) for iteration speed, since the paper fine-tunes all VLAs that way.
Be explicit about evaluation protocol (they use repeated rollouts and perturb panel position slightly during VLA evaluation to test generalization).
Takeaway you can repeat internally
This study doesn’t claim “VLA solves construction robotics.” What it does show very concretely is that in their panel manipulation benchmark:
DQN is a solid baseline and more robust than a simple MLP in their setup.
π0.5 performs strongly on the harder ground insertion task (up to 80% align success reported), and OpenVLA fails in this configuration.
The “practical effort” angle matters: VLA is framed as reducing programming effort, while DQN may need more tuning work (including added noise) to become robust.
And for AEC teams, the most actionable lesson might be the least glamorous one: build a repeatable demonstration + logging pipeline, because that’s what turns “robot demo” into “robot skill iteration.”
This blog post is based on research by Zhaofeng Hu, Hongrui Yu, Vaidhyanathan Chandramouli, and Ci-Jyun Liang, published in the paper “Sample-Efficient Robot Skill Learning for Construction Tasks: Benchmarking Hierarchical Reinforcement Learning and Vision-Language-Action VLA Model.”