


Curious about how AI can chat with 3D Scanned Point Cloud Data?
Breaking Down the Latest Breakthrough in 3D Vision-Language Technology for AEC

My takeaways from research paper : 3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment
Recent research in artificial intelligence has primarily focused on understanding 2D images, but our built environment exists in three dimensions. A new research paper introduces 3D-VisTA, a multimodal ai architecture that aims to bridge the gap between 3D spaces and natural language. Let's explore what this research means for the future of AEC technology.

The Core Innovation
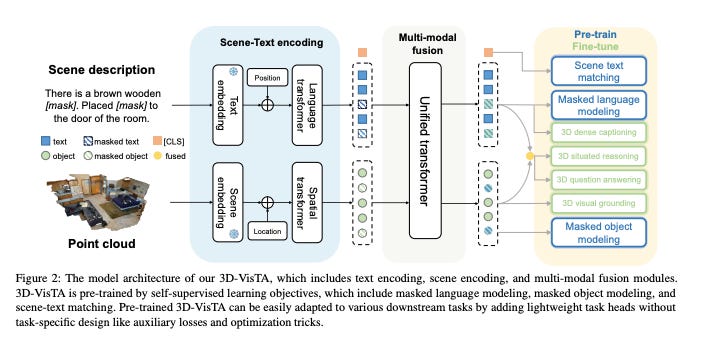
3D-VisTA represents a new approach to how AI systems process three-dimensional spaces. The key innovation lies in its unified architecture that can handle multiple types of spatial understanding tasks:
Visual Grounding: Locating specific objects based on text descriptions
Dense Captioning: Generating descriptions of objects in a space
Question Answering: Responding to spatial queries
Situated Reasoning: Understanding relative positions and relationships
What makes this particularly interesting is that previous systems required specific components for each task, while 3D-VisTA uses a simpler, unified approach.

Technical Achievement
The research demonstrates several significant improvements over previous systems:
Improved accuracy in object location tasks (8.1% improvement in specific benchmarks)
Better performance in object description tasks (10.1% improvement)
More efficient learning with less training data (achieving strong results with 30-40% of typical data requirements)
These improvements were achieved using indoor room scans from standardized datasets (ScanNet and 3R-Scan), providing a foundation for potential future applications.
Current Limitations
It's important to understand the current limitations of this research:
Data Requirements
Works with pre-processed 3D scans
Currently limited to indoor environments
Requires high-quality point cloud data
Tested primarily on standardized research datasets
Technical Constraints
Relies on accurate object segmentation
Limited to static environments
Not yet tested in real-world construction settings
Potential Future Applications for AEC
While the research is still at an academic stage, it suggests several potential future applications:
Scan Documentation
More intuitive ways to query 3D scan data
Potential for automated description of scanned spaces
Improved spatial relationship analysis
As-Built Documentation
Possibility for natural language queries of scan data
Potential for automated space description
Future applications in deviation analysis
Research Implications
The research points to several important developments:
Unified Architecture
Demonstrates that a single system can handle multiple spatial understanding tasks
Shows potential for more efficient processing of 3D data
Suggests new directions for spatial AI research

Data Efficiency
Shows that better results are possible with less training data
Indicates potential for more practical applications
Points to more efficient development pathways
Conclusion
3D-VisTA represents an important research milestone in how AI systems can understand built environments. While it's still in the research phase, it demonstrates the potential for more intuitive and efficient ways of processing spatial information.