
CEQuest: Reality Check for AI in Construction Estimating
CEQuest benchmarks LLMs on drawing interpretation and estimating. See where models fail and what AEC teams must design around.

CEQuest: what this benchmark teaches us about shipping AI for estimating
There’s a specific kind of wrong you see when you ask a general-purpose LLM an estimating question.
Not “2+2=5” wrong.
More like: it does the math, then applies the wrong professional habit the kind that makes an estimator wince.
This paper introduces CEQuest, a benchmark dataset created to evaluate LLMs on two construction tasks that are both foundational and failure-prone: construction drawing interpretation and construction estimation (quantity takeoff + costing).
The value of CEQuest isn’t just the leaderboard. It’s that it captures the kinds of mistakes that matter in real AEC workflows: formatting drift, missing final selections, plausible-but-flawed reasoning, and a lack of domain practice embedded in the model outputs.
Let’s walk through what CEQuest is, what the experiments found, and what that should change about how we implement LLM features in AEC tools.
What CEQuest is?
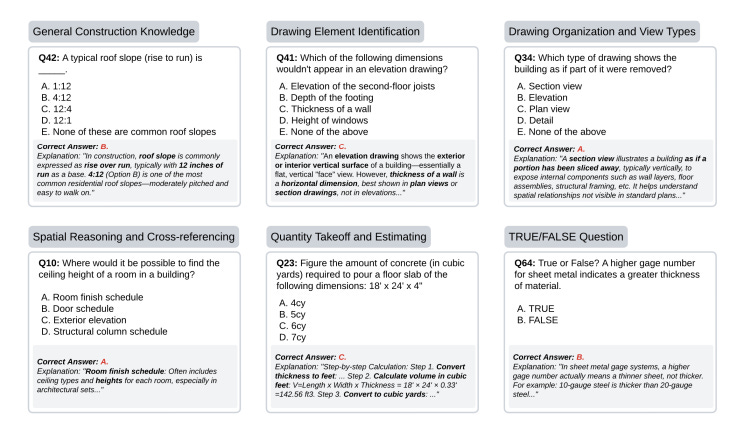
CEQuest is a curated QA dataset designed to cover “core competencies” in drawing interpretation and estimation from drawing literacy and spatial understanding through takeoff and estimating.
As a pilot study, it contains 164 questions, collected and designed by domain experts using estimating textbooks, drawing interpretation guides, and real-world instructional practice.
It includes two question types:
101 multiple-choice (62%)
63 TRUE/FALSE (38%)
The dataset is stored as structured JSON with:
a problem ID
question text
correct answer (boolean or labeled option)
options list (for multiple-choice)
The benchmark groups questions into five subject areas aligned with learning stages:
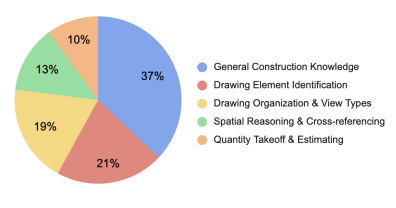
General construction knowledge
Drawing element identification
Drawing organization + view types
Spatial reasoning + cross-referencing
Quantity takeoff + estimating
The paper also states the dataset and source code are provided on GitHub, and that CEQuest will be publicly released as an open-source project with community contributions encouraged.
How they evaluate models and why this matters for “production reality”
They measure three metrics:
Accuracy (percent correct)
Execution/Evaluation time (how long evaluation takes)
Model size (resource requirements)
They also use consistent prompting for multiple-choice, e.g., “Please answer with only the letter…”
That small detail ends up being a big deal, because the case study shows models still frequently deviate from the expected output format.
Experimental setup + results what the benchmark showed
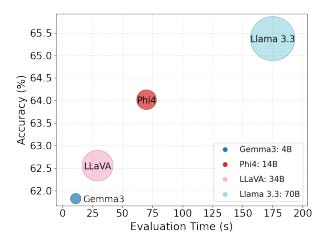
They evaluate five LLMs:
Gemma 3 (4B)
Phi4 (14B)
LLaVA (34B)
Llama 3.3 (70B)
GPT-4.1
They report mean±std across five runs.
Performance (Accuracy %):
Gemma3:4b — 61.83±0.30
Phi4:14b — 64.02±0.55
LLaVA:34b — 62.56±1.06
Llama 3.3:70b — 65.37±0.60
GPT-4.1 — 75.37±1.13
The paper highlights three observations:
All models are below 80% accuracy, even though CEQuest is described as a relatively straightforward multi-choice dataset.
GPT-4.1 is highest (and there’s a notable gap between proprietary and open-source).
Model size doesn’t always correlate with accuracy (Phi4 14B outperforming LLaVA 34B is the example given).
The failure modes that matter most for AEC workflows
1) Structured output is brittle
Even when the prompt asks for “only the letter,” models often drift.
The paper gives a concrete example: for Q10, LLaVA:34b outputs “A. Room finish schedule” instead of just “A.”
It also notes cases where models provide lengthy explanations but fail to indicate the final choice, e.g., Llama 3.3 omitting the option selection in some questions.
Why AEC folks should care: If you’re using an LLM inside a workflow that expects a clean, machine-readable output (like a takeoff line item, a classification label, or a chosen option), you should assume formatting errors will happen because the benchmark shows they do.
2) Domain-specific estimating practice is missing
The most “real-world” example is Q23:
The calculated concrete slab volume is 5.33 cubic yards
Several models pick Option B (5 cy) because it’s the closest integer
But the paper points out that professional estimating practice typically rounds up, not to the nearest whole number, to ensure enough material and account for waste.
Why AEC folks should care: This is not a “math problem.” It’s a “construction practice” problem.
Context: why the paper argues benchmarks like this are needed
The paper frames construction as a domain full of unstructured data (drawings, schedules, specs, reports) and emphasizes that drawing interpretation is difficult due to lack of standardization, varying scales, obscured information, and the limits of traditional OCR/basic CV.
It also positions CEQuest as filling a benchmark gap, since general LLM benchmarks don’t capture construction-specific modalities and reasoning needs.
And in related work, it notes LLM applications in construction have included:
processing unstructured construction docs (specs, drawings, contracts, standards) for information extraction and automated compliance checking
safety query/analysis around OSHA guidelines and incident records
project planning and scheduling (activity extraction, dependency mapping, resource allocation)
What this means for AEC product builders
Everything below is implementation guidance, not claims from the paper just a practical response to the failure modes CEQuest documents.
A) If outputs must be structured, treat formatting as a first-class risk
CEQuest shows models deviating from expected “single letter” outputs.
So in product terms: validate outputs before downstream use, and be prepared to re-ask or constrain outputs when they don’t match the contract.
B) Encode estimating conventions explicitly (don’t expect the model to “know the craft”)
The rounding example demonstrates missing domain practice.
So: capture conventions like rounding direction, waste assumptions, and ordering logic as explicit rules/policies in your system (whether that’s in instructions, configuration, or checks).
C) Evaluate models on the tasks you actually ship
The paper evaluates accuracy, time, and model size that trio maps closely to real constraints (quality, latency, cost).
So if you’re shipping “estimating assistant” features, you’ll want your own benchmark slices that mirror your user workflows, and measure those same trade-offs.
The grounded takeaway
CEQuest doesn’t say “LLMs are useless in estimating.” It shows something more actionable:
Models can answer many questions correctly
But they still struggle with format reliability and domain-specific reasoning habits
And the overall accuracy being under 80% across all tested models is a clear signal that “drop-in LLM = estimator” is not the right mental model.
For AEC teams, the practical path is: use LLMs where they shine (language + explanation + drafting), and design the surrounding system so domain rules and structured outputs don’t depend on model vibes.
This blog post is based on research by Xiaodong Zhang, Zeeshan Ahmed, Weizhen Wang, Kasun W. Thilakaratne, and Hao Qin, published in the paper “CEQuest: Benchmarking LLMs on Construction Estimation Reasoning.”