
AI for Building Code Tables: What Works
Direct image QA beats LaTeX for code tables, and LoRA fine-tuning boosts VLM accuracy on NBCC 2020 table questions.

Building codes are long, dense documents, and finding precise answers can be time-consuming. The paper frames automated question answering as a way to help AEC professionals access code information faster.
Their broader architectural direction is multimodal Retrieval-Augmented Generation (MRAG): retrieve relevant content (text/images), then generate an answer from what was retrieved.
But this study zooms in on a particularly hard slice of that problem: answering questions in building code PDFs.
The technical setup: two ways to “feed” a table to a VLM
The authors compare two input methods for Visual Question Answering (VQA) over code:
1) Direct input method (image → VLM → answer)
You give the model the page image containing the table plus the question, in a chat-like message format.
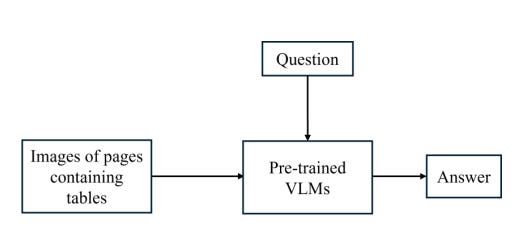
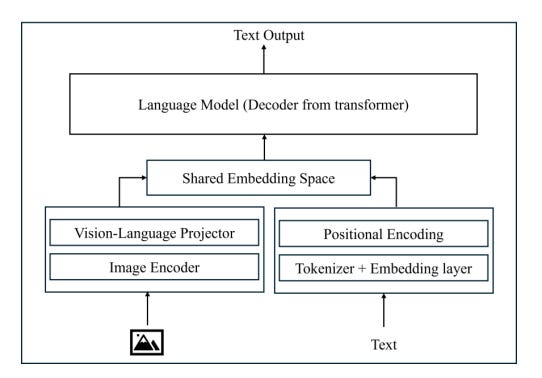
2) Indirect input method (image → LaTeX → VLM → answer)
You first convert the table image into LaTeX, then ask the model to answer based on that LaTeX representation. In their dataset preparation, the table-to-LaTeX conversion was done using GPT-4.1-2025-04-14.
Key results
Direct beat indirect on accuracy
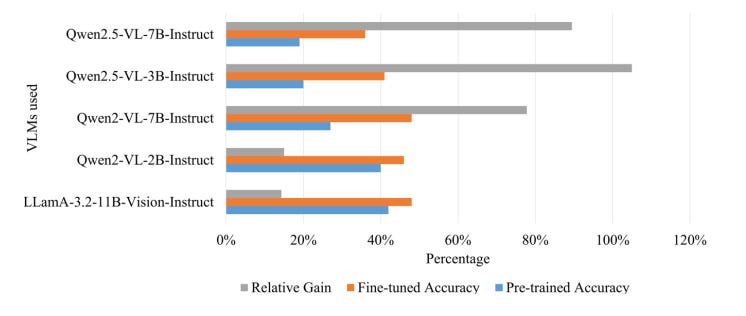
For one example model they report explicitly: LLaMA-3.2-11B-Vision-Instruct hit 42% accuracy with direct input vs 39% with indirect input; the paper says the same trend held across other evaluated VLMs.
They attribute indirect underperformance to:
the complexity/abstraction of LaTeX, and
conversion errors introduced during image→LaTeX generation.
Overall accuracy remained “relatively low”
Even though direct was better, the paper notes accuracy was still relatively low for some models, motivating fine-tuning.
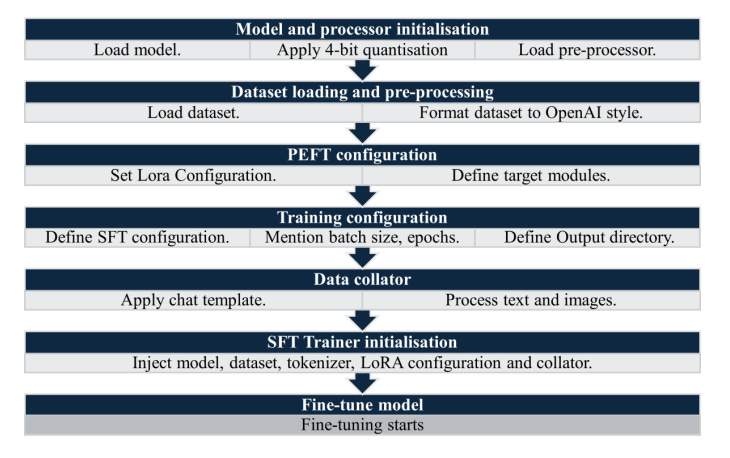
What improved performance: LoRA fine-tuning and why that matters
To address low accuracy, the authors fine-tuned all models using LoRA, a parameter-efficient method that:
freezes original weights,
inserts small trainable low-rank matrices in selected layers,
and reduces compute needs compared to full fine-tuning.
They also used BitsAndBytesConfig for 4-bit quantization to reduce GPU memory during fine-tuning.
Dataset used for fine-tuning
They generated 500 image–question–answer triplets from NBCC tables, using 400 for fine-tuning and 100 for testing.
They note using 400 samples is a limitation and suggest expanding the dataset in future work.
Gains after fine-tuning
The paper reports LoRA consistently improved performance, with relative accuracy gains ranging from 14.29% to 105%, and Qwen2.5-VL-3B-Instruct showing the largest relative improvement (105%).
Evaluation approach important detail if you care about “how did they judge correctness?”
They stored model outputs and compared them to ground truth using InternVL3-8B, which classified each answer as correct/incorrect given the ground truth.
What this means for AEC tech
Everything below is a practical interpretation of the paper’s findings not a claim that the paper built a full production system.
1) If your “code assistant” can’t handle tables, it will have a blind spot
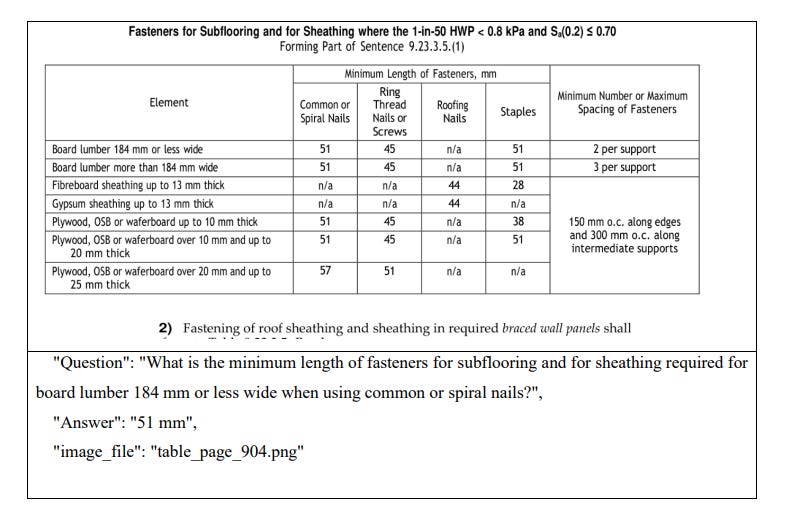
The paper explicitly describes code tables as “dense” and “rule-heavy,” often with numeric ranges, merged columns, and multi-row headers, which demands careful alignment of visual structure and text queries.
So if you’re building an AEC workflow that needs reliable answers (e.g., “what’s the minimum ___ for ___?”), tables are a high-risk zone.
2) Prefer direct table images over converting to LaTeX
In this study, direct input was consistently better than the indirect LaTeX route, and the authors point to LaTeX complexity + conversion errors as likely causes.
Implementation implication: if you’re designing a pipeline today, you’d likely want a “direct vision QA” path for table-heavy pages rather than relying on an intermediate conversion step that can introduce errors.
3) Lightweight domain adaptation is a real lever
The big story here isn’t “pick the best pretrained model.” It’s: specialize it.
LoRA improved performance across models, with some very large relative gains.
And because LoRA is parameter-efficient and compatible with low-precision loading, it’s more feasible than full fine-tuning for teams without massive training budgets.
4) Dataset creation + traceability matters
Their dataset generation process links each QA pair to an image filename to support inspection and fine-tuning workflows.
For AEC implementations, that design choice maps nicely to compliance needs: you want a system that can always point back to “which table image did this come from?”
Practical AEC use cases
Based on what the paper demonstrates (table VQA + domain adaptation), here are realistic directions an AEC team could explore:
Table-first “code lookup” assistants
A tool that answers narrow, table-based questions and returns: the value, the table page reference, and the associated headers used (traceability inspired by their image-linked dataset design).Jurisdiction-specific adapters
Fine-tune LoRA adapters per code set (NBCC/IBC/local amendments) rather than expecting one generic model to generalize. The paper’s gains support the value of domain adaptation on NBCC tables.MRAG-style document QA that doesn’t ignore images
The paper positions MRAG as a promising approach for automated QA over building codes by integrating multiple data formats.A pragmatic build would retrieve both text chunks and page images when tables are likely involved.
Honest limits
Accuracy is not “solved” here direct input helps, LoRA helps, but the paper still calls out low overall accuracy and “considerable room for improvement.”
Training data size is limited (400 fine-tune samples), and they explicitly suggest expanding it and exploring additional tuning/analysis.
They mention future work toward a complete end-to-end MRAG framework using the fine-tuned model at its core.
The takeaway for AEC tech builders
If you’re building AI for code compliance, this paper’s practical message is:
Tables need a dedicated strategy (direct visual input performs better than LaTeX conversion in this study).
Domain tuning matters LoRA can materially improve a VLM’s ability to reason over code tables without full retraining.
Traceability isn’t optional their dataset links QA pairs to specific table images, which is exactly the direction compliance tools need to go.
This blog post is based on research by Mohammad Aqib, Mohd Hamza, Ying Hei Chui, and Qipei Mei, published in the paper “Table Comprehension in Building Codes using Vision Language Models and Domain-Specific Fine-Tuning.”